
Guest post by Jonathan W. Y. Gray.
How do researchers, journalists, and artists work with archived pages from the Internet Archive’s Wayback Machine? What kinds of tools, methods, and approaches do they use? What other kinds of tools might support critical and creative repurposing of archived web materials?
As web archives have come to play an increasingly important role in understanding, reporting on, and engaging with digital culture, there are opportunities for learning and sharing across these areas of practice.
On 9 February, Internet researchers gathered at the Internet Archive Europe‘s space in Amsterdam to share different ways of working with the Wayback Machine. Many collaborate with journalists and media organisations on digital investigations. Some of us also have an artistic practice involving working with online materials.
How is the Wayback Machine used?
We split into pairs and small groups to review ways of working with web archives in our own research and teaching practices, as well as in digital investigations and media art.
In the room, there was a wealth of experience in working with the Wayback Machine over many decades. For example, in 2008, Richard, Esther, and colleagues used archived snapshots to make a short screencast documentary exploring changes to the front page of Google.
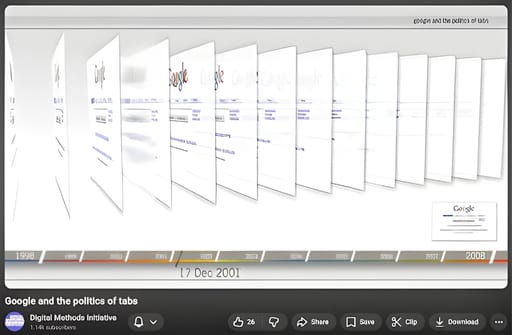
This approach to exploring archived pages through making screencast documentaries is written up in the Digital Methods and Doing Digital Methods books, which many of us use in our teaching.
Beyond interface changes, we looked at how web archives are used to trace other kinds of socio-technical transformations. For example, we spoke about research which uses the Wayback Machine to study changes in source code, moderation policies, blogospheres, national webs, country domains, social media platforms, and their availability across web archives, “follower factories” and social media engagement markets, web trackers, and mobile app ecosystems. In media research, archived pages are also used to trace changes to platform policies and practices, monetisation infrastructures, and the evolution of contested claims online.
We reviewed tools that enable this kind of research with the Wayback Machine, from the Digital Methods Initiative’s link collecting and network-making tools to a dedicated extension for the open source 4CAT: Capture and Analysis Toolkit, which supports working with collections of archived pages. We explored the broader ecology of tools for supporting different ways of working with the Wayback Machine, from archived tweets to historical Google analytics codes.

Several of us had also worked with journalists in collaborations involving the Wayback Machine, including on the circulation and monetisation of misinformation. We looked further into how journalists use the Wayback Machine, including to make databases of delicensed doctors and to investigate identity fraud. We found further insights into journalistic practices through things like blog posts, documentation, and training materials. This is an area we’d like to spend more time on as part of our respective digital investigations research groups.
We looked at some examples of how the Wayback Machine is used by artists and talked about how it can be used in the process, as well as the final pieces of media artists. It can be hard to find out about how artists use the Wayback Machine, as descriptions of work often do not mention or link to it. Idil, a researcher and artist, spoke about her subcultural nostalgia in revisiting vampirefreaks.com and how this might inspire her artistic practice.
We’d like to have further gatherings and events with journalists and artists to further understand how they work with the Wayback Machine and how we might learn from, collaborate with, and support each other.
How might we work with the Wayback Machine in the future?
After reviewing how the Wayback Machine has been used in our research and by various communities of practice, we considered how we might work with it in the future.

We spoke about the geographies of the Wayback Machine and how we might study things like the breadth, depth, and frequency of archiving different top-level domains—including to see which countries and regions might be under-represented in web archives, as well as reviewing what kinds of prominent websites might be missing.
Another thread was how we might contribute to the Wayback Machine as Internet researchers, for example, by adding a 4CAT feature to submit collections of URLs to the Wayback Machine, or by curating digital culture collections on the Internet Archive related to topics we’re working on (such as this collection of COVID-19 mobile apps).

We thought it could be interesting to support an ecology of archived materials that are shared in different ways, using tools such as ArchiveBox for locally hosted materials, and sharing curated subsets to the Internet Archive. We also discussed ways to query across multiple collections of archived materials, such as through the Memento aggregator.
We considered how social media posts are archived by the Wayback Machine and approaches to working with patchily archived materials. One idea was to look back at archived social media interfaces to reconstruct how posts looked at different moments in time.
What next?
In terms of next steps, we will continue to explore the threads above across our respective classes and projects. We’d also like to organise some co-learning and practice-sharing workshops with researchers, journalists, and artists – as well as having some speculative prototyping and tiny tool-making sessions to surface and seed other ways of working with the Wayback Machine.
If you’re interested in keeping in touch about these activities, we’ve set up a web-archives mailing list for researchers, educators, journalists and artists working with the Wayback Machine and other web archives.
We hope that growing connections across these communities of practice will contribute to critical and creative uses of web archives in years ahead.
This event was co-organised by Jonathan W. Y. Gray and Beatrice Murch as part of a series of collaborations around repurposing web archives. It was supported by Internet Archive Europe, Public Data Lab, the Centre for Digital Culture at King’s College London, the Digital Methods Initiative, and the Deep Culture project, University of Amsterdam. Participants included Varvara Boboc, Anthony Burton, Zachary Furste, Idil Galip, Marloes Geboers, Alex Gekker, Alice Bouzada Goulart, Sal Hagen, David Kousemaker, Stijn Peeters, Richard Rogers, Marc Tuters, Lonneke van der Velden, Dale Wahl and Esther Weltevrede. Thanks to Liliana Bounegru, Thais Lobo, Anne Helmond, and Fernando van der Vlist for their additional input.

